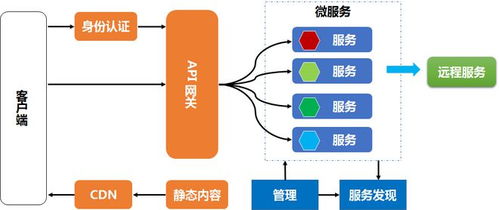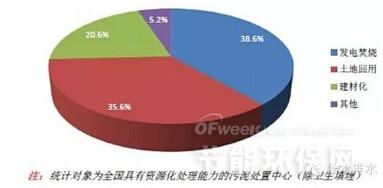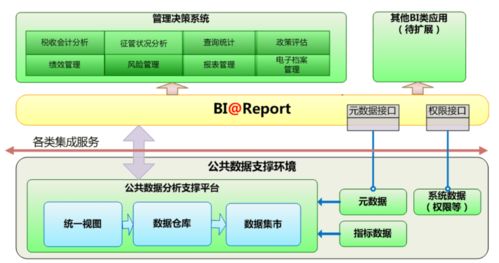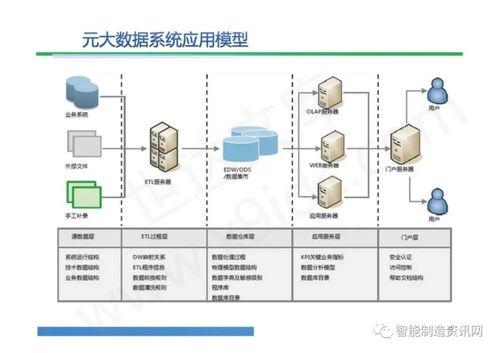
Apache Spark作为一种快速、通用的大规模数据处理引擎,广泛应用于数据分析与机器学习领域。下面从分区、系统架构、算子和任务提交方式四个方面详细介绍Spark技术栈的核心概念。
一、分区(Partitioning)
Spark的数据处理基于分布式数据集(RDD、DataFrame等),分区是数据划分的基本单位。每个分区是数据的一个子集,可以并行处理。分区策略包括:
1. 默认分区:根据数据源和集群配置自动划分。
2. 自定义分区:通过repartition()或coalesce()调整分区数量,或使用partitionBy()按键分区,优化数据本地性和负载均衡。
合理分区能显著提升并行效率,避免数据倾斜。
二、系统架构(System Architecture)
Spark采用主从架构,核心组件包括:
1. Driver:运行用户程序的JVM进程,负责解析代码、生成执行计划并调度任务。
2. Cluster Manager:资源管理器(如Standalone、YARN、Mesos),分配集群资源。
3. Executor:在工作节点上运行的进程,执行具体任务并缓存数据。
执行流程:Driver将作业拆分为任务,通过Cluster Manager分配给Executor并行执行。
三、算子(Operators)
Spark算子分为转换(Transformation)和行动(Action)两类:
1. 转换算子:惰性执行,生成新RDD/DataFrame,如map()、filter()、groupBy()。
2. 行动算子:触发实际计算并返回结果,如count()、collect()、saveAsTextFile()。
算子优化(如谓词下推、广播连接)能减少Shuffle操作,提升性能。
四、任务提交方式(Job Submission)
Spark支持多种任务提交模式:
- 本地模式:通过
local[*]在单机模拟分布式环境,适用于测试。 - 集群模式:
- Standalone:使用Spark内置资源管理器。
- YARN/Mesos:与Hadoop或其他集群框架集成。
提交命令示例:spark-submit --master yarn --deploy-mode cluster app.jar。
五、数据处理流程
典型数据处理步骤:
1. 读取数据源(如HDFS、Kafka)创建RDD/DataFrame。
2. 应用转换算子进行过滤、聚合等操作。
3. 通过行动算子输出结果或保存至存储系统。
Spark的内存计算和DAG调度器确保高效执行,适用于批处理、流处理和迭代计算。
掌握分区策略、架构原理、算子特性及提交方式,是构建高效Spark应用的关键。结合实际数据特征调整配置,可充分发挥其分布式计算优势。