在当今数字驱动的世界中,数据已成为企业决策和运营的核心资源。为了最大化数据的价值,组织必须有效管理数据的生命周期,这通常涉及三个关键概念:数据治理、数据集成和数据处理。本文将对这三个概念进行全面解析。
一、数据治理
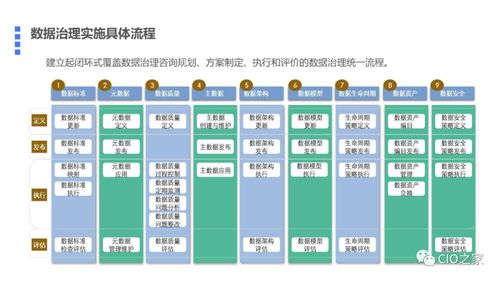
数据治理是一套框架和流程,旨在确保数据在整个组织中的质量、安全性、可用性和一致性。它涉及定义策略、标准、角色和责任,以管理数据资产。数据治理的目标包括:
- 数据质量管理:通过监控和修复数据错误,确保数据的准确性、完整性和可靠性。
- 数据安全与合规性:保护数据免受未授权访问,并遵守相关法规(如GDPR或CCPA)。
- 数据所有权与问责制:明确数据所有者,确保数据使用符合业务目标。
- 元数据管理:记录数据的来源、定义和关系,提高数据可理解性。
有效的数据治理有助于降低风险、提高决策质量,并支持数据驱动的文化。
二、数据集成
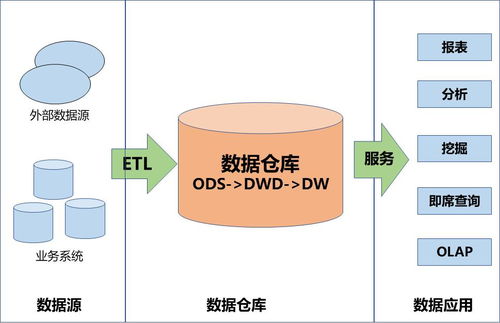
数据集成是指将来自不同来源(如数据库、应用程序或外部系统)的数据合并到一个统一的视图或存储中,以提供一致、全面的信息。常见的数据集成方法包括:
- ETL(提取、转换、加载):从源系统提取数据,进行清洗和转换,然后加载到目标系统(如数据仓库)。
- ELT(提取、加载、转换):类似ETL,但转换步骤在加载后执行,适用于大数据场景。
- 数据虚拟化:在不移动数据的情况下,提供统一的逻辑视图,适合实时查询。
- API集成:通过应用程序接口连接不同系统,实现数据共享。
数据集成的优势包括消除数据孤岛、提高数据可访问性,并支持分析和报告。它也可能面临数据格式不一致、延迟和安全性等挑战。
三、数据处理
数据处理是指对原始数据进行操作,以提取有价值的信息或转换为所需格式。它包括多个阶段:
- 数据收集:从各种来源(如传感器、日志或用户输入)获取数据。
- 数据清洗:处理缺失值、重复项和错误,确保数据质量。
- 数据转换:将数据标准化、聚合或丰富,以适应分析需求。
- 数据存储:使用数据库、数据湖或云存储保存数据。
- 数据分析与可视化:应用统计方法或机器学习模型,生成见解并通过图表展示。
数据处理可以分为批处理(处理大量历史数据)和流处理(实时处理数据流)。现代技术如Hadoop、Spark和Kafka已极大地提升了处理效率。
总结
数据治理、数据集成和数据处理是数据管理生态系统的三大支柱。数据治理提供策略和规则,确保数据可靠和安全;数据集成打破数据孤岛,实现信息统一;数据处理则从原始数据中提取价值。组织需要协调这些环节,以构建强大的数据基础设施,从而推动创新和竞争优势。随着人工智能和物联网的发展,这些概念将继续演化,要求企业持续投资于数据能力建设。