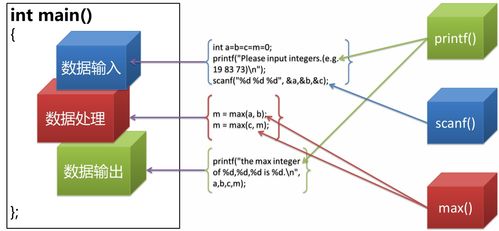
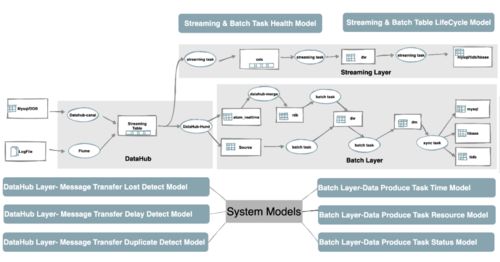
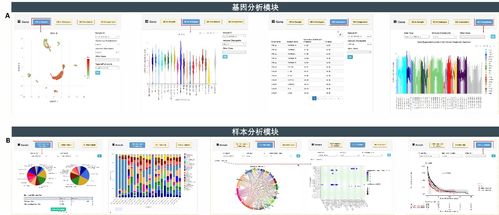
在数据驱动的时代,文本数据作为非结构化数据的主要形式,其规模正以前所未有的速度增长。从社交媒体评论、新闻资讯、学术文献到企业日志、客服对话,文本大数据蕴含着巨大的价值。要有效挖掘这些价值,一个经过精心设计的、能够提供强大存储支持服务的底层架构至关重要。本文旨在探讨文本大数据存储支持服务的设计核心与关键考量。
一、设计核心:分层、弹性与智能化
文本大数据存储支持服务的设计绝非简单的磁盘阵列堆砌,而是一个融合了数据全生命周期管理的系统工程。其核心设计理念应围绕以下三点展开:
- 分层存储策略:根据文本数据的访问频率、价值密度和处理要求,将其划分为热数据、温数据和冷数据。热数据(如实时分析中的近期日志)需要部署在高性能的SSD或内存数据库中,以保证毫秒级响应;温数据(如过去数月的业务文档)可存放在性能与成本均衡的分布式文件系统(如HDFS)或对象存储中;冷数据(如合规性要求的多年存档)则可迁移至成本极低的磁带库或冰川式对象存储。智能的数据生命周期管理策略能自动完成数据在不同层级间的流动,实现成本与性能的最优平衡。
- 弹性可扩展架构:文本数据的增长是持续且难以精确预测的。因此,存储架构必须具备水平扩展能力,能够通过增加节点来近乎线性地提升存储容量和吞吐量。云原生的对象存储服务(如AWS S3、阿里云OSS)或自建的基于Ceph、MinIO的分布式存储系统是理想选择。它们不仅提供了近乎无限的扩展性,还天然支持多副本或纠删码机制,保障数据的高可用性和持久性。
- 智能化元数据与索引服务:海量文本的價值解锁依赖于高效的检索与分析。存储系统需要提供强大的元数据管理能力,为每份文本数据打上丰富的标签(如来源、生成时间、主题、情感倾向、关键实体等)。需要集成或提供接口供上层应用构建倒排索引、向量索引(用于语义搜索)等。将索引与原始数据分离但关联存储,是提升查询性能的常见做法。智能化的数据接入服务应能自动完成文本的初步解析、元数据提取和索引构建。
二、关键服务组件
一个完整的存储支持服务体系,通常由以下关键组件协同构成:
- 分布式文件/对象存储层:作为数据的最终承载层,提供高可靠、高可用的基础存储能力。对象存储因其平坦的命名空间和优异的扩展性,已成为文本大数据的主流存储方案。
- 数据接入与总线服务:提供标准化的API(如RESTful API、Kafka接口)来接收来自各种源头(FTP、日志采集器、应用直接写入)的文本数据流。该服务需具备缓冲、流量控制、格式验证和初步路由能力。
- 元数据管理与目录服务:作为存储系统的“大脑”,集中管理所有数据的元信息,提供数据发现、血缘追踪、权限映射和策略执行(如生命周期管理、加密)功能。
- 索引与查询加速服务:独立或集成部署的索引引擎(如Elasticsearch, OpenSearch),专门处理文本的全文检索、聚合分析请求。存储系统需与其深度集成,确保数据同步的一致性。
- 数据安全与治理服务:贯穿始终的安全层,提供静态加密、传输加密、细粒度访问控制(基于角色或属性)、审计日志以及合规性数据保留/删除策略。
- 监控与运维支持服务:对存储集群的健康状态、性能指标(IOPS、吞吐量、延迟)、容量使用率进行全方位监控,并提供自动化运维工具,如故障自愈、均衡调度、容量预测告警等。
三、技术选型考量与挑战
在设计实践中,技术选型需综合权衡:
- 规模与性能:数据量级(PB/EB级)和并发访问需求决定了是采用HDFS(适合大文件、批处理)还是对象存储(适合海量小文件、高并发)。
- 生态集成:存储系统是否能与主流的大数据处理框架(如Spark、Flink)、分析工具及云服务无缝集成,减少数据搬迁成本。
- 成本控制:总拥有成本(TCO)包括硬件/云资源成本、运维人力成本和能源消耗。分层存储和压缩/去重技术是降低成本的关键。
- 语义化处理支持:随着NLP技术的发展,存储层是否能为 embedding 向量存储、大语言模型(LLM)的微调数据管理提供原生支持,正成为一个新的考量点。
面临的挑战主要包括:如何设计高效的压缩算法以降低海量文本的存储开销;如何在保障查询性能的实现极致的存储成本优化;以及如何构建统一的服务接口,屏蔽底层存储的复杂性,为上层多样化的应用提供一致、便捷的数据访问体验。
四、结论
文本大数据的存储支持服务设计,是一个以数据为中心、以服务为导向的架构命题。它不再仅仅是提供存储空间,更是要提供一个涵盖数据摄入、组织、管理、保护和供应的综合性平台。成功的核心在于深刻理解业务的数据访问模式和价值需求,从而设计出分层清晰、弹性伸缩、智能管理且安全可靠的存储服务体系。只有这样,才能让文本数据这座“矿山”的挖掘工作变得高效、经济且可持续,真正赋能于智能搜索、舆情分析、风险控制、商业洞察等高级应用,释放文本大数据的全部潜能。