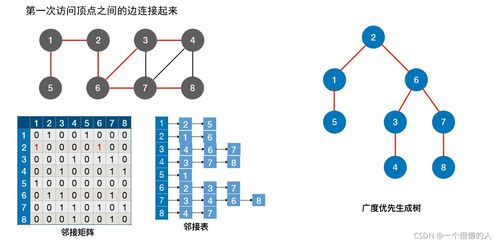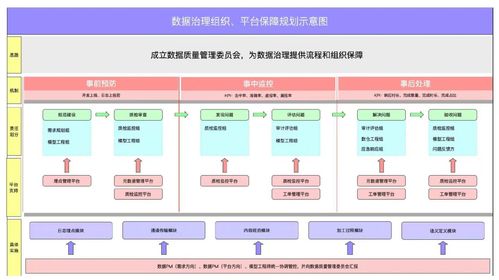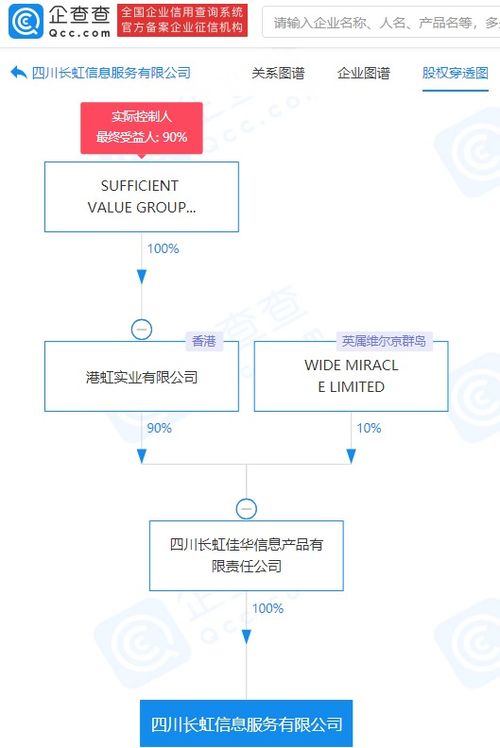
数据处理是当今信息时代的核心环节,涉及从原始数据中提取有价值信息的过程。随着大数据、人工智能和物联网技术的快速发展,高效的数据处理方法变得尤为重要。
数据处理的基本流程
数据处理通常包含四个关键步骤:
- 数据收集:从各种来源获取原始数据,包括数据库、传感器、社交媒体等
- 数据清洗:处理缺失值、异常值和重复数据,确保数据质量
- 数据转换:将数据转换为适合分析的格式,包括规范化、聚合和特征工程
- 数据存储:将处理后的数据存储在适当的数据仓库或数据湖中
现代数据处理技术
批处理与流处理
传统批处理适合处理大量历史数据,而流处理技术如Apache Kafka和Apache Flink能够实时处理数据流,满足现代企业对实时洞察的需求。
云计算与分布式计算
云平台如AWS、Azure和Google Cloud提供了可扩展的数据处理服务,而分布式计算框架如Apache Spark大幅提升了海量数据处理效率。
数据湖与数据仓库
数据湖存储原始格式的所有数据,而数据仓库存储经过处理的结构化数据,两者结合形成了现代数据架构的基础。
数据处理的最佳实践
- 建立数据治理框架:确保数据质量、安全性和合规性
- 采用自动化流程:减少人工干预,提高处理效率和准确性
- 实施监控机制:实时跟踪数据处理过程,及时发现和解决问题
- 注重数据安全:在数据处理全周期实施适当的安全措施
未来趋势
人工智能和机器学习正深度融入数据处理流程,自动化数据清洗、智能特征工程和预测性分析将成为标准配置。边缘计算的发展将使数据处理更接近数据源,减少延迟并提高效率。
数据处理不仅是技术挑战,更是业务转型的关键驱动力。组织需要持续优化数据处理能力,才能在数据驱动的竞争环境中保持优势。